
Demystifying AI dubbing - Part 3: Text-To-Speech with F5-TTS
In the first part of the series, we discussed the different parts involved in a modern dubbing pipeline:
- Speech To Text - Convert an audio source into text
- Translation - Translate text from the source language to the target language
- Text To Speech - Produce speech from the text translation in step 2
- Lip sync - Synchronize lip movements of characters in a video with an audio source
In the second part, we dove into the speech to text component of the dubbing pipeline. We understood how speech-to-text works by diving into a concrete example in Whisper.
In this part, we’ll discuss the next step. We’ll transform the text transcribed in the previous step to natural sounding speech, cloning the speaker’s voice and generating new audio from text.
As a reference to learn how a modern TTS system works, we’ll use F5-TTS, a state-of-the-art open-source Text-To-Speech model available at https://github.com/SWivid/F5-TTS.
F5-TTS
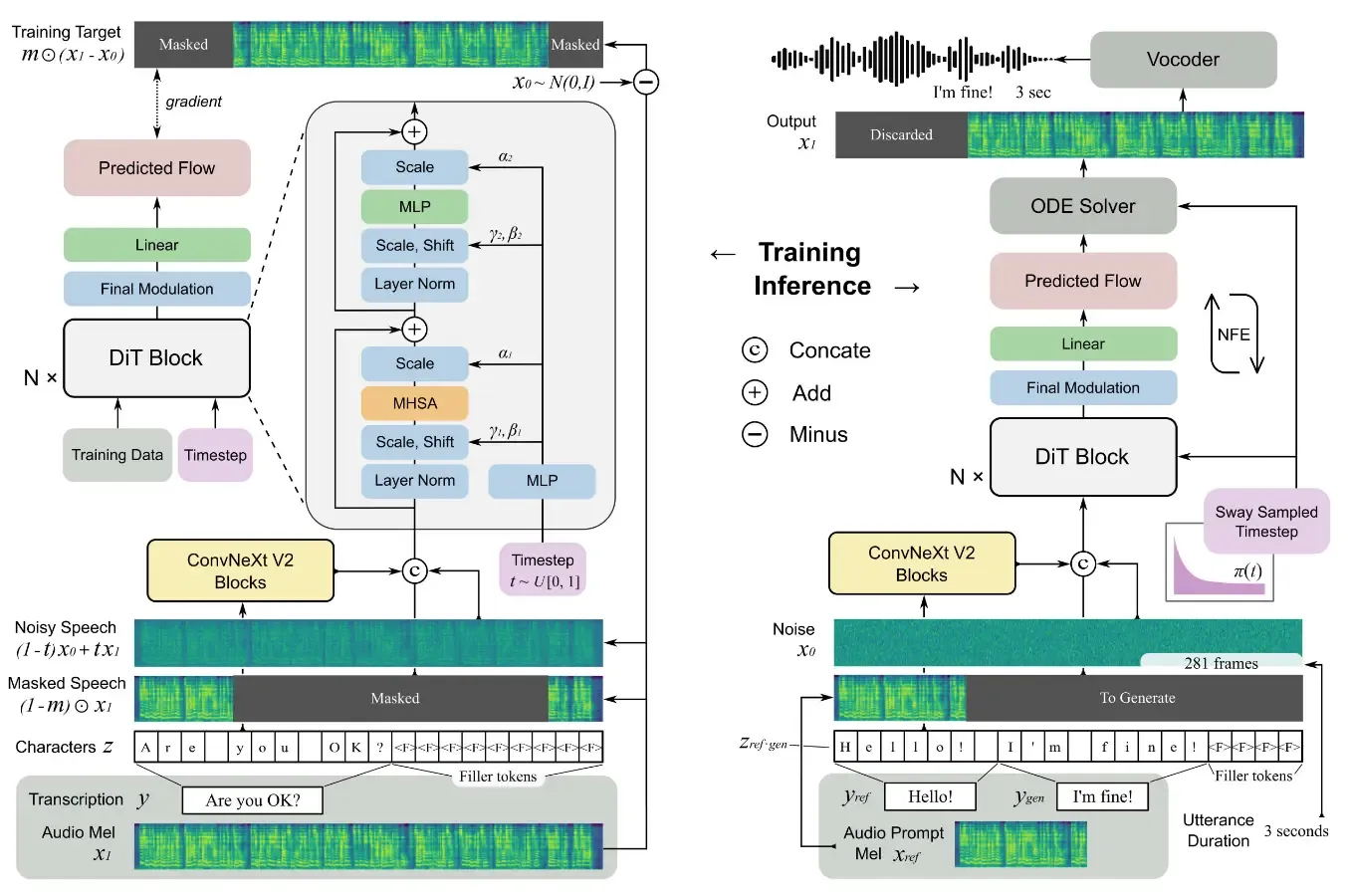
F5-TTS is a recently published Text-To-Speech model that can clone a speaker’s voice and, given a text prompt, produce natural-sounding audio from text.
The model is comprised of the following components:
- A Conditional Flow Matching (CFM) pipeline, used to generate audio (in the form of a mel-spectrogram) using the Diffusion Transformer.
- A Diffusion Transformer, used as part of the CFM to iteratively produce natural sounding audio (in the form of a mel-spectrogram) given the speaker audio and text
- A Vocoder, used to decode the final audio in the form of a mel-spectrogram to audio
The F5-TTS flow starts with the main function
def main():
...
reg1 = r"(?=\[\w+\])"
chunks = re.split(reg1, gen_text)
...
generated_audio_segments = []
...
for text in chunks:
...
gen_text_ = text.strip()
...
audio_segment, final_sample_rate, spectrogram = infer_process(
ref_audio_,
ref_text_,
gen_text_,
ema_model,
vocoder,
...
)
generated_audio_segments.append(audio_segment)
...
final_wave = np.concatenate(generated_audio_segments)
...
with open(wave_path, "wb") as f:
sf.write(f.name, final_wave, final_sample_rate)The function receives (via global variables parsed from commandline arguments):
- gen_text - The text to generate
- ref_audio - A reference audio file of the speaker’s voice to clone
- ref_text - A reference text translation of the speaker’s voice in ref_audio
It then splits the text into chunks, runs them through infer_process, which generates audio, concatenates the audio segments back together and saves them to a new audio file.
So what does infer_process do?
def infer_process(
...
):
...
# Split the input text into batches
gen_text_batches = chunk_text(gen_text, max_chars=max_chars)
return next(
infer_batch_process(
...
gen_text_batches,
...
)
)It splits the text into sentences and calls infer_batch_process as a generator to generate audio per sentence (per call).
Let’s look into infer_batch_process, which is the main logic in this loop.
def infer_batch_process(
ref_audio,
ref_text,
gen_text_batches,
model_obj,
vocoder,
...
):
audio, sr = ref_audio
if audio.shape[0] > 1:
audio = torch.mean(audio, dim=0, keepdim=True)
rms = torch.sqrt(torch.mean(torch.square(audio)))
if rms < target_rms:
audio = audio * target_rms / rms
generated_waves = []
spectrograms = []
def process_batch(gen_text):
...
with torch.inference_mode():
generated, _ = model_obj.sample(
cond=audio,
text=final_text_list,
duration=duration,
steps=nfe_step,
cfg_strength=cfg_strength,
sway_sampling_coef=sway_sampling_coef,
)
generated = generated.to(torch.float32) # generated mel spectrogram
generated = generated[:, ref_audio_len:, :]
generated = generated.permute(0, 2, 1)
...
generated_wave = vocoder.decode(generated)
if rms < target_rms:
generated_wave = generated_wave * rms / target_rms
# wav -> numpy
generated_wave = generated_wave.squeeze().cpu().numpy()
for j in range(0, len(generated_wave), chunk_size):
yield generated_wave[j : j + chunk_size], target_sample_rate
for gen_text in progress.tqdm(gen_text_batches) if progress is not None else gen_text_batches:
for chunk in process_batch(gen_text):
yield chunkThis loop is responsible for the following:
- Iterates over gen_text_batches, each element of which is a sentence.
- Runs model_obj.sample on each sentence, generating a mel-spectrogram using a Continuous Flow Matching pipeline.
- Runs a vocoder on the mel-spectrogram, generating a waveform.
- Each waveform is split into chunk_size pieces and yielded one-by-one.
infer_batch_process is basically a generator yielding audio chunks lazily.
It’s now clear that the main parts responsible for the core logic of F5-TTS are the CFM and the vocoder. So let’s dive in.
Continuous Flow Matching
Continuous Flow Matching is a method used to sample from probability distributions (e.g., generating audio or images) by learning to predict the final output in one step, given a noise input.
This is in contrast to Denoising Diffusion Probabilistic Models (DDPMs), which require multiple (usually hundreds) of steps to generate a natural-looking image.
The high performance penalty of DDPMs is a major obstacle for building robust video and audio generative models, as both audio and video require generating a new frame or waveform many times to produce the full work.
In F5-TTS, the authors make use of CFM models to drastically improve the generation speed by training a CFM model, requiring significantly fewer steps for generating highly realistic audio.
The core logic for the CFM is implemented in the sample procedure, let’s see exactly how it works.
def sample(
self,
cond: float["b n d"] | float["b nw"], # noqa: F722 # Reference Audio
text: int["b nt"] | list[str], # noqa: F722 # Text to generate
duration: int | int["b"], # noqa: F821
*,
lens: int["b"] | None = None, # noqa: F821
...
):
...
batch, cond_seq_len, device = *cond.shape[:2], cond.device
...
cond_mask = lens_to_mask(lens)
...
step_cond = torch.where(
cond_mask, cond, torch.zeros_like(cond)
) # allow direct control (cut cond audio) with lens passed in
if batch > 1:
mask = lens_to_mask(duration)
else: # save memory and speed up, as single inference need no mask currently
mask = None
def fn(t, x):
...
# predict flow (cond and uncond), for classifier-free guidance
pred_cfg = self.transformer(
x=x,
cond=step_cond,
text=text,
time=t,
mask=mask,
cfg_infer=True,
cache=True,
)
pred, null_pred = torch.chunk(pred_cfg, 2, dim=0)
return pred + (pred - null_pred) * cfg_strength
# noise input
# to make sure batch inference result is same with different batch size, and for sure single inference
# still some difference maybe due to convolutional layers
y0 = []
for dur in duration:
...
y0.append(torch.randn(dur, self.num_channels, device=self.device, dtype=step_cond.dtype))
...
t = torch.linspace(t_start, 1, steps + 1, device=self.device, dtype=step_cond.dtype)
...
t = t + sway_sampling_coef * (torch.cos(torch.pi / 2 * t) - 1 + t)
trajectory = odeint(fn, y0, t, **self.odeint_kwargs)
...
sampled = trajectory[-1]
out = sampled
...
if exists(vocoder):
...
out = vocoder(out)
return out, trajectoryThe sample function proceeds as follows:
- Generate random noise as the initial state for the model.
- Generate uniform timestamps between 0 and 1 to represent the progression from noise to clean audio.
- Call fn, a function that predicts the flow vector field at each timestep using the Diffusion Transformer, conditioned on:
- speaker audio (reference)
- text to generate
- timestep
- current noisy state
- Use ODE numerical integration to iteratively transform the random noise into a clean mel-spectrogram at timestep 1.0 (the final encoded audio representation).
- Run the mel-spectrogram through a vocoder (vocos: closing the gap between time-domain and fourier-based neural vocoders for high-quality audio synthesis) to decode it into a wave output, producing the final audio waveform
The function does a few interesting things worth noting. First, the Diffusion Transformer uses classifier-free guidance to produce “noise predictions” (i.e., the flow vector field). This works by running the model twice - once conditioned on the speaker audio and text, and once unconditioned. The two outputs are combined using a weighted difference controlled by cfg_strength. This effectively “guides” the model towards producing outputs more aligned with the conditioning, improving fidelity without requiring a separate classifier.
Second, F5-TTS uses sway sampling to slightly perturb the uniform timesteps in the ODE solver. Instead of strictly linear interpolation between timesteps, it adds a cosine-shaped offset. This helps the model avoid getting stuck in local minima during integration and can improve diversity and quality of generated outputs, especially in regions where the vector field changes rapidly.
Finally, the usage of ODE integration (via torchdiffeq) provides a major advantage over DDPMs. Rather than requiring hundreds of forward passes to iteratively denoise (as in diffusion models), the ODE solver can integrate across timesteps in far fewer steps. This drastically reduces generation time while maintaining high quality. Essentially, it treats the generation process as solving a continuous-time differential equation from random noise to clean audio.
The bulk of the remaining logic hides inside the Diffusion Transformer, so how does this transformer predict the flow map? Let’s have a look.
Diffusion Transformer
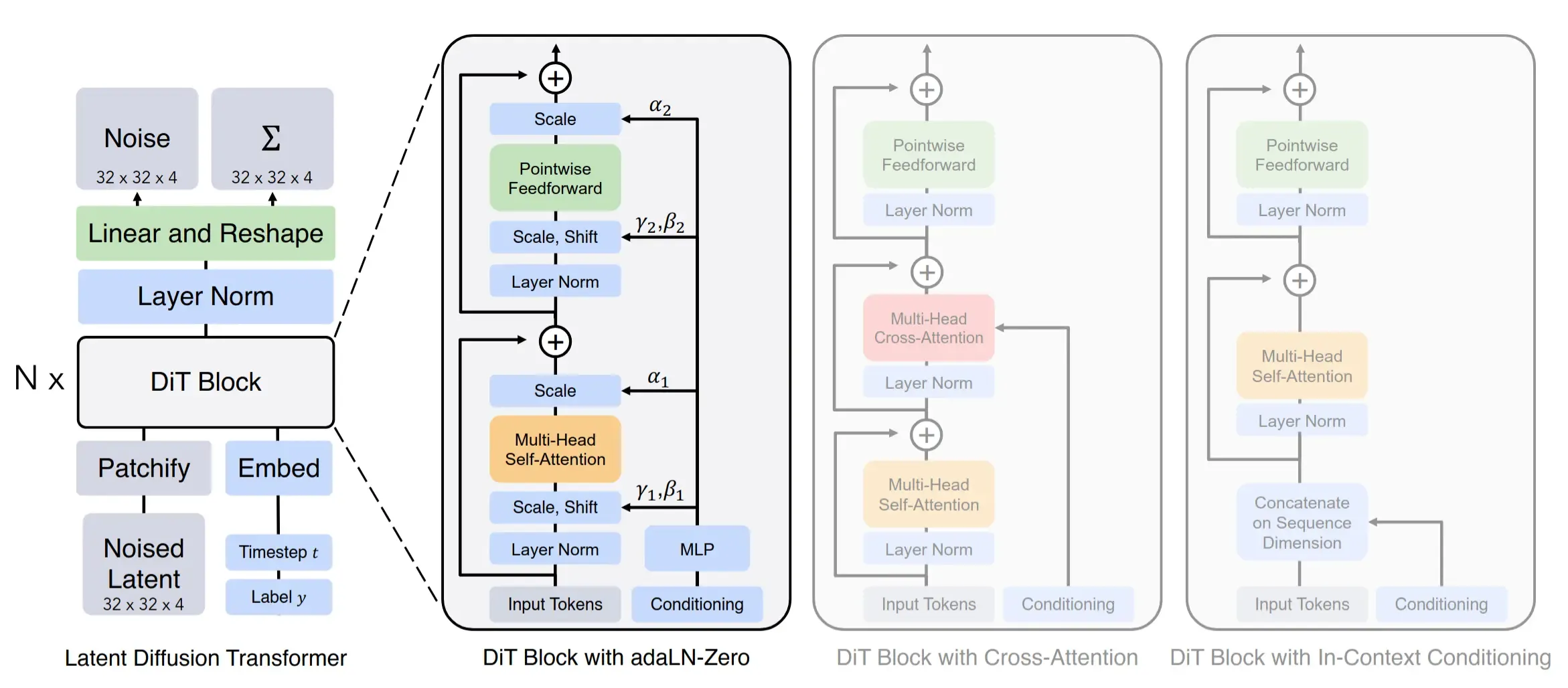
This definitely warrants an entire blog to cover in-depth, but for our purposes, a brief review of the Diffusion Transformer architecture, initially presented in Scalable Diffusion Models with Transformers used for generating the final mel-spectrogram will suffice.
class DiT(nn.Module):
def __init__(
...
):
self.time_embed = TimestepEmbedding(dim)
...
self.text_embed = TextEmbedding(
text_num_embeds, text_dim, mask_padding=text_mask_padding, conv_layers=conv_layers
)
self.input_embed = InputEmbedding(mel_dim, text_dim, dim)
self.rotary_embed = RotaryEmbedding(dim_head)
...
self.transformer_blocks = nn.ModuleList(
[
DiTBlock(
...
)
for _ in range(depth)
]
)
...
self.norm_out = AdaLayerNorm_Final(dim) # final modulation
self.proj_out = nn.Linear(dim, mel_dim)
...
def forward(
self,
x: float["b n d"], # nosied input audio # noqa: F722
cond: float["b n d"], # masked cond audio # noqa: F722
text: int["b nt"], # text # noqa: F722
time: float["b"] | float[""], # time step # noqa: F821 F722
mask: bool["b n"] | None = None, # noqa: F722
drop_audio_cond: bool = False, # cfg for cond audio
drop_text: bool = False, # cfg for text
...
cache: bool = False,
):
batch, seq_len = x.shape[0], x.shape[1]
if time.ndim == 0:
time = time.repeat(batch)
# 1. Timestamp Embedding
# t: conditioning time, text: text, x: noised audio + cond audio + text
t = self.time_embed(time)
# 2. Classifier Free Guidance
x_cond = self.get_input_embed(x, cond, text, drop_audio_cond=False, drop_text=False, cache=cache)
x_uncond = self.get_input_embed(x, cond, text, drop_audio_cond=True, drop_text=True, cache=cache)
x = torch.cat((x_cond, x_uncond), dim=0)
t = torch.cat((t, t), dim=0)
mask = torch.cat((mask, mask), dim=0) if mask is not None else None
...
# 3. Transformer blocks
for block in self.transformer_blocks:
x = block(x, t, mask=mask, rope=rope)
# Layer norm
x = self.norm_out(x, t)
# Linear transformation to make the output fit the expected output dimensions
output = self.proj_out(x)
return outputThe Diffusion Transformer forward function works as follows:
- The current timestamp is embedded by the timestamp embedding layer
# t: conditioning time, text: text, x: noised audio + cond audio + text
t = self.time_embed(time)
class SinusPositionEmbedding(nn.Module):
def __init__(self, dim):
super().__init__()
self.dim = dim
def forward(self, x, scale=1000):
device = x.device
half_dim = self.dim // 2
emb = math.log(10000) / (half_dim - 1)
emb = torch.exp(torch.arange(half_dim, device=device).float() * -emb)
emb = scale * x.unsqueeze(1) * emb.unsqueeze(0)
emb = torch.cat((emb.sin(), emb.cos()), dim=-1)
return emb
class TimestepEmbedding(nn.Module):
def __init__(self, dim, freq_embed_dim=256):
super().__init__()
self.time_embed = SinusPositionEmbedding(freq_embed_dim)
self.time_mlp = nn.Sequential(nn.Linear(freq_embed_dim, dim), nn.SiLU(), nn.Linear(dim, dim))
def forward(self, timestep: float["b"]):
time_hidden = self.time_embed(timestep)
time_hidden = time_hidden.to(timestep.dtype)
time = self.time_mlp(time_hidden) # b d
return time
- Classifier-free guidance is performed using the input (Conditional and unconditional embeddings are calculated for the input)
# 2. Classifier Free Guidance
x_cond = self.get_input_embed(x, cond, text, drop_audio_cond=False, drop_text=False)
x_uncond = self.get_input_embed(x, cond, text, drop_audio_cond=True, drop_text=True)
x = torch.cat((x_cond, x_uncond), dim=0)
t = torch.cat((t, t), dim=0)
mask = torch.cat((mask, mask), dim=0) if mask is not None else NoneWhich works as follows:
def get_input_embed(
self,
x, # b n d
cond, # b n d
text, # b nt
drop_audio_cond: bool = False,
drop_text: bool = False,
cache: bool = True,
):
seq_len = x.shape[1]
text_embed = self.text_embed(text, seq_len, drop_text=drop_text)
x = self.input_embed(x, cond, text_embed, drop_audio_cond=drop_audio_cond)
return xThe text is embedded using an embedding layer, positional encoding is added, and it is run through ConvNeXt V2 blocks. It is then passed, together with the noise (x) and speaker audio (cond) into the input_embed function, which runs it through a linear layer and a convolutional position embedding (adding a skip connection)
class TextEmbedding(nn.Module):
def __init__(self, text_num_embeds, text_dim, mask_padding=True, conv_layers=0, conv_mult=2):
super().__init__()
self.text_embed = nn.Embedding(text_num_embeds + 1, text_dim) # use 0 as filler token
self.mask_padding = mask_padding # mask filler and batch padding tokens or not
if conv_layers > 0:
self.extra_modeling = True
self.precompute_max_pos = 4096 # ~44s of 24khz audio
self.register_buffer("freqs_cis", precompute_freqs_cis(text_dim, self.precompute_max_pos), persistent=False)
self.text_blocks = nn.Sequential(
*[ConvNeXtV2Block(text_dim, text_dim * conv_mult) for _ in range(conv_layers)]
)
...
def forward(self, text: int["b nt"], seq_len, drop_text=False): # noqa: F722
text = text + 1 # use 0 as filler token. preprocess of batch pad -1, see list_str_to_idx()
text = text[:, :seq_len] # curtail if character tokens are more than the mel spec tokens
batch, text_len = text.shape[0], text.shape[1]
text = F.pad(text, (0, seq_len - text_len), value=0)
if self.mask_padding:
text_mask = text == 0
if drop_text: # cfg for text
text = torch.zeros_like(text)
text = self.text_embed(text) # b n -> b n d
# possible extra modeling
if self.extra_modeling:
# sinus pos emb
batch_start = torch.zeros((batch,), dtype=torch.long)
pos_idx = get_pos_embed_indices(batch_start, seq_len, max_pos=self.precompute_max_pos)
text_pos_embed = self.freqs_cis[pos_idx]
text = text + text_pos_embed
# convnextv2 blocks
...
text = self.text_blocks(text)
return text
class InputEmbedding(nn.Module):
def __init__(self, mel_dim, text_dim, out_dim):
super().__init__()
self.proj = nn.Linear(mel_dim * 2 + text_dim, out_dim)
self.conv_pos_embed = ConvPositionEmbedding(dim=out_dim)
def forward(self, x: float["b n d"], cond: float["b n d"], text_embed: float["b n d"], drop_audio_cond=False): # noqa: F722
if drop_audio_cond: # cfg for cond audio
cond = torch.zeros_like(cond)
x = self.proj(torch.cat((x, cond, text_embed), dim=-1))
x = self.conv_pos_embed(x) + x
return x- The Transformer blocks are sequentially executed by passing the output of each layer as the input of the next layer.
# 3. Transformer blocks
for block in self.transformer_blocks:
x = block(x, t, mask=mask, rope=rope)Finally, the output is normalized and projected to the expected dimensions.
# Layer norm
x = self.norm_out(x, t)
# Linear transformation to make the output fit the expected output dimensions
output = self.proj_out(x)
return outputWrapping up
In this post, we explored how F5-TTS bridges the gap between text and natural-sounding audio. We dissected its core components - Conditional Flow Matching (CFM) for efficient generation and the Diffusion Transformer for modeling complex audio-text relationships.
By leveraging ODE-based integration and innovations like classifier-free guidance and sway sampling, F5-TTS achieves high-quality results in significantly fewer steps than traditional diffusion models - an essential feature for real-time applications like AI dubbing.
But our journey doesn’t stop at generating audio. In the next post, we’ll dive into LatentSync and see how we synchronize the generated speech with video, creating new facial expressions and lip movements that match the dubbed audio naturally.