Demystifying AI Dubbing - Part 2: Speech-to-Text with Whisper
In the first part of this series, we discussed the main components of a dubbing pipeline (Speech to Text, Translation, Text to Speech and Lip Syncing).
In this part, we’ll start from the beginning and discuss the speech-to-text component. The part of the pipeline responsible for transcribing the speaker audio and translating it to different languages.
Speech To Text
As mentioned in part one, modern Speech To Text pipelines are usually based on a combination of CNN & Transformers at the core of their architecture.
It would be best to explain the pipeline in detail using a concrete example. We’ll use a very popular open source model for this, Whisper (Robust Speech Recognition via Large-Scale Weak Supervision) developed by OpenAI as a reference to explain how speech-to-text works.
OpenAI open-sourced both the code and the model weights, making Whisper a widely-used foundation for modern transcription systems. The code and the model weights are available at https://github.com/openai/whisper
A deep-dive into Whisper
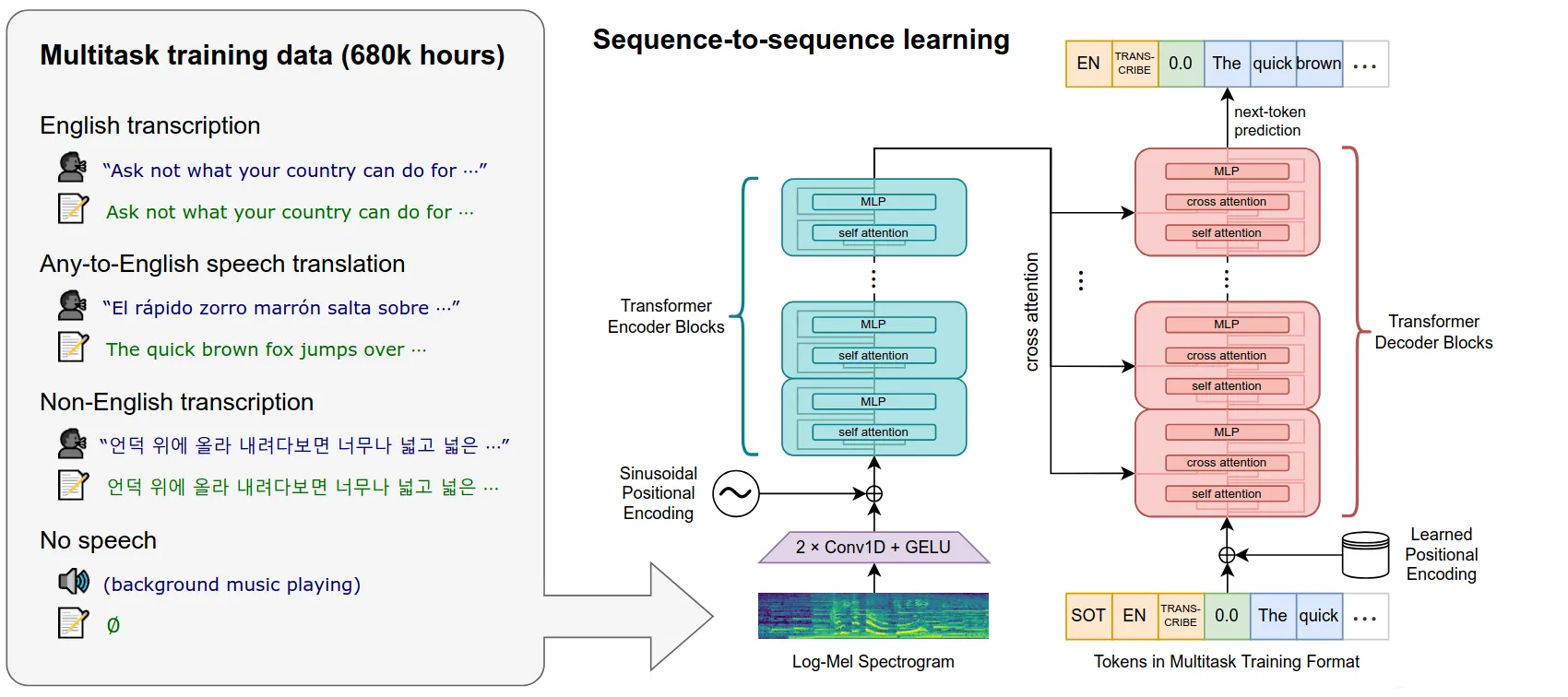
The core of the STT (Speech To Text) logic is in the model itself. Whisper takes as input an audio in the form of an audio file and can translate the audio directly to text in various languages or transcribe it, directly translating to spoken language.
The main parts of the Whisper architecture are as follows:
- Standard log-mel spectrogram transformation - transform the audio signal to the frequency domain (2D representation, per time slice)
- One-dimensional CNN used to embed the mel spectrogram into tokens (the input that transformer models work on)
- Transformer Encoder - used to encode the audio input into a latent representation
- Transformer Decoder - uses cross-attention to combine the current translation state with the audio and outputs discrete text tokens (the final output of the model)
The output of this process is a series of tokens that can be directly mapped into words / letters of the target language.
So how does this all work in practice? Let’s dive in
Preparing the scene
Whisper’s main logic starts at the transcribe function.
This function receives arguments that configure the model and executes the transcription logic, which is essentially as follows:
- Convert the audio to a mel-spectrogram
- Identify the language
- Choose a tokenizer according to the identified language
- Decode each segment of the mel spectrogram using Whisper model
def transcribe(
model: "Whisper",
audio: Union[str, np.ndarray, torch.Tensor],
...
):
# Convert the audio to a mel spectogram representation
mel = log_mel_spectrogram(audio, model.dims.n_mels, padding=N_SAMPLES)
...
# Identify the language, used to choose the appropriate tokenizer
_, probs = model.detect_language(mel_segment)
...
tokenizer = get_tokenizer(
model.is_multilingual,
num_languages=model.num_languages,
language=language,
task=task,
)
...
# Loop over the entire audio, segment by segment, and output text
with tqdm.tqdm(
total=content_frames, unit="frames", disable=verbose is not False
) as pbar:
...
# Get the current segment
mel_segment = mel[:, seek : seek + segment_size]
...
# Run Whisper model and output token ids per audio segment
result: DecodingResult = decode_with_fallback(mel_segment)
tokens = torch.tensor(result.tokens)
...
# Convert the token ids to readable text
tokenizer.decode(text_tokens),
...
We’ll look into each of the steps to understand their implementation
Mel Spectrogram Transformation
A spectrogram is a 2D representation of a signal over time, where the signal is sliced into overlapping segments, each of which is Fourier transformed to produce its frequency content.
The result is a matrix showing how the frequency spectrum evolves over time, with amplitude or power represented by color or intensity.
You can think of each time-slice as a two dimensional axis with the Y as frequency and the X (or the color) as the magnitude, as shown below.
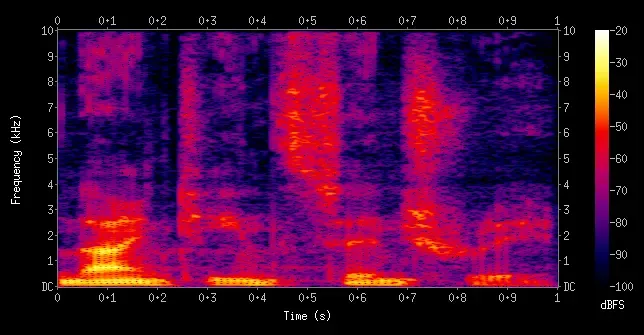
In whisper, this transformation is done in the log_mel_spectrogram.
def log_mel_spectrogram(
audio: Union[str, np.ndarray, torch.Tensor],
n_mels: int = 80,
padding: int = 0,
device: Optional[Union[str, torch.device]] = None,
):
...
window = torch.hann_window(N_FFT).to(audio.device)
stft = torch.stft(audio, N_FFT, HOP_LENGTH, window=window, return_complex=True)
magnitudes = stft[..., :-1].abs() ** 2
filters = mel_filters(audio.device, n_mels)
mel_spec = filters @ magnitudes
log_spec = torch.clamp(mel_spec, min=1e-10).log10()
log_spec = torch.maximum(log_spec, log_spec.max() - 8.0)
log_spec = (log_spec + 4.0) / 4.0
return log_specThis function:
- Splits the audio into overlapping segments.
- Applies the Short-Time Fourier Transform (STFT) to extract frequency content over time.
- Squares the output to compute magnitude (i.e., power spectrum).
- Projects the result onto the mel scale using a bank of mel filters (each representing a triangular window in frequency space).
- Applies log scaling and normalization to produce a clean, model-friendly log-mel spectrogram.
The resulting output is a [n_mels, n_segments] matrix - one mel spectrum per time slice, normalized and compressed to emphasize the most relevant signal features.
Tokenizer
Whisper uses a tokenizer that splits text, converts from integer indices to tokens (words / letters or part of words) and vice-versa. The tokenizer used is a Byte Pair Encoding (BPE) tokenizer implemented by the Python package tiktoken.
@dataclass
class Tokenizer:
"""A thin wrapper around `tiktoken` providing quick access to special tokens"""
encoding: tiktoken.Encoding
...
def encode(self, text, **kwargs):
return self.encoding.encode(text, **kwargs)
def decode(self, token_ids: List[int], **kwargs) -> str:
token_ids = [t for t in token_ids if t < self.timestamp_begin]
return self.encoding.decode(token_ids, **kwargs)
Whisper Model
The Whisper model is the core of OpenAI’s Speech-to-Text pipeline. It processes audio in chunks, transforming a mel spectrogram into transcribed or translated text using an encoder-decoder Transformer architecture.
At the heart of Whisper’s inference is the decode_with_fallback function, which processes a single mel spectrogram segment and returns a DecodingResult:
def decode_with_fallback(segment: torch.Tensor) -> DecodingResult:
...
decode_result = model.decode(segment, options)
...
return decode_resultThe decode method wraps around a DecodingTask, which manages state and decoding strategy:
def decode(
model: "Whisper",
mel: Tensor,
options: DecodingOptions = DecodingOptions(),
**kwargs,
) -> Union[DecodingResult, List[DecodingResult]]:
...
result = DecodingTask(model, options).run(mel)
return result[0] if single else resultThe run function starts by passing the mel spectrogram into the audio encoder to extract high-level audio features:
def run(self, mel: Tensor) -> List[DecodingResult]:
...
audio_features: Tensor = self._get_audio_features(mel)
...
tokens, sum_logprobs, no_speech_probs = self._main_loop(audio_features, tokens)The _get_audio_features method simply forwards the mel input to the encoder:
def _get_audio_features(self, mel: Tensor):
...
audio_features = self.model.encoder(mel)
...
return audio_featuresNext comes _main_loop, which iteratively predicts tokens, applying autoregressive decoding:
def _main_loop(self, audio_features: Tensor, tokens: Tensor):
sum_logprobs = torch.zeros(n_batch, device=audio_features.device)
...
for i in range(self.sample_len):
logits = self.inference.logits(tokens, audio_features)
logits = logits[:, -1] # get logits for next token
...
tokens, completed = self.decoder.update(tokens, logits, sum_logprobs)
if completed or tokens.shape[-1] > self.n_ctx:
break
return tokens, sum_logprobs, no_speech_probsThe logits are generated by passing both the current text tokens and the encoded audio features into the decoder:
class PyTorchInference(Inference):
...
def logits(self, tokens: Tensor, audio_features: Tensor) -> Tensor:
...
return self.model.decoder(tokens, audio_features, kv_cache=self.kv_cache)Here’s the overall Whisper model definition. It uses two components:
AudioEncoder: a convolutional + Transformer encoder stack that turns mel spectrograms into latent features.TextDecoder: a Transformer decoder that predicts text token-by-token based on both audio and previous text.
class Whisper(nn.Module):
def __init__(self, dims: ModelDimensions):
...
self.encoder = AudioEncoder(
self.dims.n_mels,
self.dims.n_audio_ctx,
self.dims.n_audio_state,
self.dims.n_audio_head,
self.dims.n_audio_layer,
)
self.decoder = TextDecoder(
self.dims.n_vocab,
self.dims.n_text_ctx,
self.dims.n_text_state,
self.dims.n_text_head,
self.dims.n_text_layer,
)
def embed_audio(self, mel: torch.Tensor):
return self.encoder(mel)
def logits(self, tokens: torch.Tensor, audio_features: torch.Tensor):
return self.decoder(tokens, audio_features)
def forward(self, mel: torch.Tensor, tokens: torch.Tensor):
return self.decoder(tokens, self.encoder(mel))This architecture allows Whisper to condition each text prediction on both the audio features and the previously predicted tokens, making it suitable for both transcription and translation tasks.
Audio Encoding
So how does Whisper encode the initial wave signal into input that a transformer model can consume?
Fortunately, the answer is not too complicated, and it can be described clearly from the full implementation of the audio encoder.
class AudioEncoder(nn.Module):
def __init__(
self, n_mels: int, n_ctx: int, n_state: int, n_head: int, n_layer: int
):
super().__init__()
self.conv1 = Conv1d(n_mels, n_state, kernel_size=3, padding=1)
self.conv2 = Conv1d(n_state, n_state, kernel_size=3, stride=2, padding=1)
self.register_buffer("positional_embedding", sinusoids(n_ctx, n_state))
self.blocks: Iterable[ResidualAttentionBlock] = nn.ModuleList(
[ResidualAttentionBlock(n_state, n_head) for _ in range(n_layer)]
)
self.ln_post = LayerNorm(n_state)
def forward(self, x: Tensor):
"""
x : torch.Tensor, shape = (batch_size, n_mels, n_ctx)
the mel spectrogram of the audio
"""
x = F.gelu(self.conv1(x))
x = F.gelu(self.conv2(x))
x = x.permute(0, 2, 1)
assert x.shape[1:] == self.positional_embedding.shape, "incorrect audio shape"
x = (x + self.positional_embedding).to(x.dtype)
for block in self.blocks:
x = block(x)
x = self.ln_post(x)
return xFollowing through the encoder’s code, we can split the logic into two parts:
- The initial embedding layers, responsible for transforming the raw audio signal into an n_state shape
- The Transformer attention blocks, responsible for mixing the information from the first step and producing the final output
The initial embedding layers (first part) are composed of two one-dimensional convolution layers, each followed by a GELU activation. These convolution layers transform the mel-frequency axis into n_state-dimensional feature representations (channels).
Before entering the Transformer, the model adds a Sinusoidal Positional Encoding, which injects information about the temporal position of each feature.
Finally, the features are passed through a self-attention layer to “mix” the values of all channels.
The choice of the transformer here is empirical, it could have been replaced by additional convolution layers or various other choices (the input is not sequential and there is nothing that makes it especially well-suited for cross-attention blocks).
Decoding Into Tokens
The Text Decoder is responsible for transforming text input (represented by a vector of token ids) and audio embeddings (encoded by the Audio Encoder) to logits.
These logits represent the likelihood distribution over the vocabulary for predicting the next token.
class TextDecoder(nn.Module):
def __init__(
self, n_vocab: int, n_ctx: int, n_state: int, n_head: int, n_layer: int
):
super().__init__()
self.token_embedding = nn.Embedding(n_vocab, n_state)
self.positional_embedding = nn.Parameter(torch.empty(n_ctx, n_state))
self.blocks: Iterable[ResidualAttentionBlock] = nn.ModuleList(
[
ResidualAttentionBlock(n_state, n_head, cross_attention=True)
for _ in range(n_layer)
]
)
...
mask = torch.empty(n_ctx, n_ctx).fill_(-np.inf).triu_(1)
self.register_buffer("mask", mask, persistent=False)
def forward(self, x: Tensor, xa: Tensor, kv_cache: Optional[dict] = None):
"""
x : torch.LongTensor, shape = (batch_size, <= n_ctx)
the text tokens
xa : torch.Tensor, shape = (batch_size, n_audio_ctx, n_audio_state)
the encoded audio features to be attended on
"""
...
x = (
self.token_embedding(x)
+ self.positional_embedding[offset : offset + x.shape[-1]]
)
...
for block in self.blocks:
x = block(x, xa, mask=self.mask, kv_cache=kv_cache)
...
logits = (
x @ torch.transpose(self.token_embedding.weight.to(x.dtype), 0, 1)
).float()
return logitsThe function begins by transforming the text (token ids) to vectors using the token_embedding layer and adds learned positional embedding to these tokens. This produces new embeddings that contain positional information (the location of each word in the sentence).
Next, the model passes the text embeddings and audio features through several cross attention blocks, effectively mixing the information in the audio signal (xa) and the input text (x). This mechanism allows the decoder to attend to the entire audio context while generating each token.
This fusion enables the model to predict the next token - whether it’s part of a transcript, a translation, or a different task (such as language prediction, which we discuss next) - by combining both audio context and previously decoded tokens (auto-regressively).
Finally, a causal attention mask is applied to the self-attention mechanism in the decoder. This mask prevents the model from attending to future tokens during inference, enforcing the autoregressive property.
Language Detection
The language detection feature is used by the pipeline to identify the language and pick the right tokenizer.
This feature is a nice example of the flexibility of the transformer decoder architecture. It leverages the whisper model audio encoder to encode the audio and the text decoder to predict the language (using a special token for that prediction).
def detect_language(
model: "Whisper", mel: Tensor, tokenizer: Tokenizer = None
) -> Tuple[Tensor, List[dict]]:
...
mel = model.encoder(mel)
# forward pass using a single token, startoftranscript
n_audio = mel.shape[0]
x = torch.tensor([[tokenizer.sot]] * n_audio).to(mel.device) # [n_audio, 1]
# Run the model text decoder and get the next predicted token
logits = model.logits(x, mel)[:, 0]
# collect detected languages; suppress all non-language tokens
mask = torch.ones(logits.shape[-1], dtype=torch.bool)
mask[list(tokenizer.all_language_tokens)] = False
logits[:, mask] = -np.inf
language_tokens = logits.argmax(dim=-1)
language_token_probs = logits.softmax(dim=-1).cpu()
language_probs = [
{
c: language_token_probs[i, j].item()
for j, c in zip(tokenizer.all_language_tokens, tokenizer.all_language_codes)
}
for i in range(n_audio)
]
...
return language_tokens, language_probsSo how does this work?
The steps proceed as follows:
- The audio features are encoded using the audio encoder.
- The SOT (Start Of Sentence) token is prepended to all features in the batch_size.
- Next, the model.logits function is used to run the text decoder with the SOT text prompt and the audio features, resulting in logits for token predictions.
- Finally, the language tokens are collected and the probabilities are calculated using the standard softmax function.
This simple process enables the pipeline to leverage the existing architecture to predict the language for each audio segment while taking advantage of the extensive training process (with multiple objectives) to further improve the language prediction.
Wrapping up
In this post, we took a deep dive into the first stage of the AI dubbing pipeline: Speech-to-Text. Using OpenAI’s Whisper as a case study, we explored how raw audio is transformed into accurate transcriptions through a series of carefully designed steps—from mel spectrogram conversion to Transformer-based decoding.
We broke down each part of the pipeline:
- How audio is converted into a model-friendly format
- How Whisper tokenizes and decodes text
- How it uses attention to connect audio with text output
- And how language detection is seamlessly integrated into the model
This component lays the foundation for the rest of the dubbing pipeline. High-quality transcriptions are critical—they directly impact the accuracy of translation, synthesis, and ultimately lip-sync.
In part 3 of this series, we explore translation - how can we easily translate from almost any language to any other language? using a concrete example, We’ll dive deep into Large Language Models (LLMs). When we’re done, we’ll know exactly how they work.